This is an archived version of the documentation. View the latest version here.
Initial revision: 2015-03-05
Last updated: 2015-03-09
This doc: tinyurl.com/ubernetesv2
Slides: tinyurl.com/ubernetes-slides
Today, each Kubernetes cluster is a relatively self-contained unit, which typically runs in a single "on-premise" data centre or single availability zone of a cloud provider (Google's GCE, Amazon's AWS, etc).
Several current and potential Kubernetes users and customers have expressed a keen interest in tying together ("federating") multiple clusters in some sensible way in order to enable the following kinds of use cases (intentionally vague):
The above use cases are by necessity left imprecisely defined. The rest of this document explores these use cases and their implications in further detail, and compares a few alternative high level approaches to addressing them. The idea of cluster federation has informally become known as_ "Ubernetes"_.
TBD
A central design concept in Kubernetes is that of a cluster. While loosely speaking, a cluster can be thought of as running in a single data center, or cloud provider availability zone, a more precise definition is that each cluster provides:
The above in turn imply the need for a relatively performant, reliable and cheap network within each cluster.
There is also assumed to be some degree of failure correlation across a cluster, i.e. whole clusters are expected to fail, at least occasionally (due to cluster-wide power and network failures, natural disasters etc). Clusters are often relatively homogenous in that all compute nodes are typically provided by a single cloud provider or hardware vendor, and connected by a common, unified network fabric. But these are not hard requirements of Kubernetes.
Other classes of Kubernetes deployments than the one sketched above are technically feasible, but come with some challenges of their own, and are not yet common or explicitly supported.
More specifically, having a Kubernetes cluster span multiple well-connected availability zones within a single geographical region (e.g. US North East, UK, Japan etc) is worthy of further consideration, in particular because it potentially addresses some of these requirements.
Let's name a few concrete use cases to aid the discussion:
"I want to preferentially run my workloads in my on-premise cluster(s), but automatically "overflow" to my cloud-hosted cluster(s) when I run out of on-premise capacity."
This idea is known in some circles as "cloudbursting".
Clarifying questions: What is the unit of overflow? Individual pods? Probably not always. Replication controllers and their associated sets of pods? Groups of replication controllers (a.k.a. distributed applications)? How are persistent disks overflowed? Can the "overflowed" pods communicate with their brethren and sistren pods and services in the other cluster(s)? Presumably yes, at higher cost and latency, provided that they use external service discovery. Is "overflow" enabled only when creating new workloads/replication controllers, or are existing workloads dynamically migrated between clusters based on fluctuating available capacity? If so, what is the desired behaviour, and how is it achieved? How, if at all, does this relate to quota enforcement (e.g. if we run out of on-premise capacity, can all or only some quotas transfer to other, potentially more expensive off-premise capacity?)
It seems that most of this boils down to:
"I want most of my workloads to run in my preferred cloud-hosted cluster(s), but some are privacy-sensitive, and should be automatically diverted to run in my secure, on-premise cluster(s). The list of privacy-sensitive workloads changes over time, and they're subject to external auditing."
Clarifying questions: What kinds of rules determine which workloads go where? Is a static mapping from container (or more typically, replication controller) to cluster maintained and enforced? If so, is it only enforced on startup, or are things migrated between clusters when the mappings change? This starts to look quite similar to "1. Capacity Overflow", and again seems to boil down to:
"My CTO wants us to avoid vendor lock-in, so she wants our workloads to run across multiple cloud providers at all times. She changes our set of preferred cloud providers and pricing contracts with them periodically, and doesn't want to have to communicate and manually enforce these policy changes across the organization every time this happens. She wants it centrally and automatically enforced, monitored and audited."
Clarifying questions: Again, I think that this can potentially be reformulated as a Capacity Overflow problem - the fundamental principles seem to be the same or substantially similar to those above.
"I want to be immune to any single data centre or cloud availability zone outage, so I want to spread my service across multiple such zones (and ideally even across multiple cloud providers), and have my service remain available even if one of the availability zones or cloud providers "goes down".
It seems useful to split this into two sub use cases:
The single cloud provider case might be easier to implement (although the multi-cloud provider implementation should just work for a single cloud provider). Propose high-level design catering for both, with initial implementation targeting single cloud provider only.
Clarifying questions:
How does global external service discovery work? In the steady
state, which external clients connect to which clusters? GeoDNS or
similar? What is the tolerable failover latency if a cluster goes
down? Maybe something like (make up some numbers, notwithstanding
some buggy DNS resolvers, TTL's, caches etc) ~3 minutes for ~90% of
clients to re-issue DNS lookups and reconnect to a new cluster when
their home cluster fails is good enough for most Kubernetes users
(or at least way better than the status quo), given that these sorts
of failure only happen a small number of times a year?
How does dynamic load balancing across clusters work, if at all? One simple starting point might be "it doesn't". i.e. if a service in a cluster is deemed to be "up", it receives as much traffic as is generated "nearby" (even if it overloads). If the service is deemed to "be down" in a given cluster, "all" nearby traffic is redirected to some other cluster within some number of seconds (failover could be automatic or manual). Failover is essentially binary. An improvement would be to detect when a service in a cluster reaches maximum serving capacity, and dynamically divert additional traffic to other clusters. But how exactly does all of this work, and how much of it is provided by Kubernetes, as opposed to something else bolted on top (e.g. external monitoring and manipulation of GeoDNS)?
How does this tie in with auto-scaling of services? More specifically, if I run my service across n clusters globally, and one (or more) of them fail, how do I ensure that the remaining n-1 clusters have enough capacity to serve the additional, failed-over traffic? Either:
Doing nothing (i.e. forcing users to choose between 1 and 2 on their own) is probably an OK starting point. Kubernetes autoscaling can get us to 3 at some later date.
Up to this point, this use case ("Unavailability Zones") seems materially different from all the others above. It does not require dynamic cross-cluster service migration (we assume that the service is already running in more than one cluster when the failure occurs). Nor does it necessarily involve cross-cluster service discovery or location affinity. As a result, I propose that we address this use case somewhat independently of the others (although I strongly suspect that it will become substantially easier once we've solved the others).
All of the above (regarding "Unavailibility Zones") refers primarily to already-running user-facing services, and minimizing the impact on end users of those services becoming unavailable in a given cluster. What about the people and systems that deploy Kubernetes services (devops etc)? Should they be automatically shielded from the impact of the cluster outage? i.e. have their new resource creation requests automatically diverted to another cluster during the outage? While this specific requirement seems non-critical (manual fail-over seems relatively non-arduous, ignoring the user-facing issues above), it smells a lot like the first three use cases listed above ("Capacity Overflow, Sensitive Services, Vendor lock-in..."), so if we address those, we probably get this one free of charge.
As we saw above, a few common challenges fall out of most of the use cases considered above, namely:
Can the pods comprising a single distributed application be partitioned across more than one cluster? More generally, how far apart, in network terms, can a given client and server within a distributed application reasonably be? A server need not necessarily be a pod, but could instead be a persistent disk housing data, or some other stateful network service. What is tolerable is typically application-dependent, primarily influenced by network bandwidth consumption, latency requirements and cost sensitivity.
For simplicity, lets assume that all Kubernetes distributed applications fall into one of three categories with respect to relative location affinity:
And then there's what I'll call absolute location affinity. Some applications are required to run in bounded geographical or network topology locations. The reasons for this are typically political/legislative (data privacy laws etc), or driven by network proximity to consumers (or data providers) of the application ("most of our users are in Western Europe, U.S. West Coast" etc).
Proposal: First tackle Strictly Decoupled applications (which can be trivially scheduled, partitioned or moved, one pod at a time). Then tackle Preferentially Coupled applications (which must be scheduled in totality in a single cluster, and can be moved, but ultimately in total, and necessarily within some bounded time). Leave strictly coupled applications to be manually moved between clusters as required for the foreseeable future.
I propose having pods use standard discovery methods used by external clients of Kubernetes applications (i.e. DNS). DNS might resolve to a public endpoint in the local or a remote cluster. Other than Strictly Coupled applications, software should be largely oblivious of which of the two occurs.
Aside: How do we avoid "tromboning" through an external VIP when DNS
resolves to a public IP on the local cluster? Strictly speaking this
would be an optimization, and probably only matters to high bandwidth,
low latency communications. We could potentially eliminate the
trombone with some kube-proxy magic if necessary. More detail to be
added here, but feel free to shoot down the basic DNS idea in the mean
time.
This is closely related to location affinity above, and also discussed there. The basic idea is that some controller, logically outside of the basic Kubernetes control plane of the clusters in question, needs to be able to:
Again this is closely related to location affinity discussed above, and is in some sense an extension of Cross-cluster Scheduling. When certain events occur, it becomes necessary or desirable for the cluster federation system to proactively move distributed applications (either in part or in whole) from one cluster to another. Examples of such events include:
Strictly Decoupled applications can be trivially moved, in part or in whole, one pod at a time, to one or more clusters.
For Preferentially Decoupled applications, the federation system must first locate a single cluster with sufficient capacity to accommodate the entire application, then reserve that capacity, and incrementally move the application, one (or more) resources at a time, over to the new cluster, within some bounded time period (and possibly within a predefined "maintenance" window).
Strictly Coupled applications (with the exception of those deemed
completely immovable) require the federation system to:
It is proposed that support for automated migration of Strictly Coupled applications be deferred to a later date.
These are often left implicit by customers, but are worth calling out explicitly:
TBD: All very hand-wavey still, but some initial thoughts to get the conversation going...
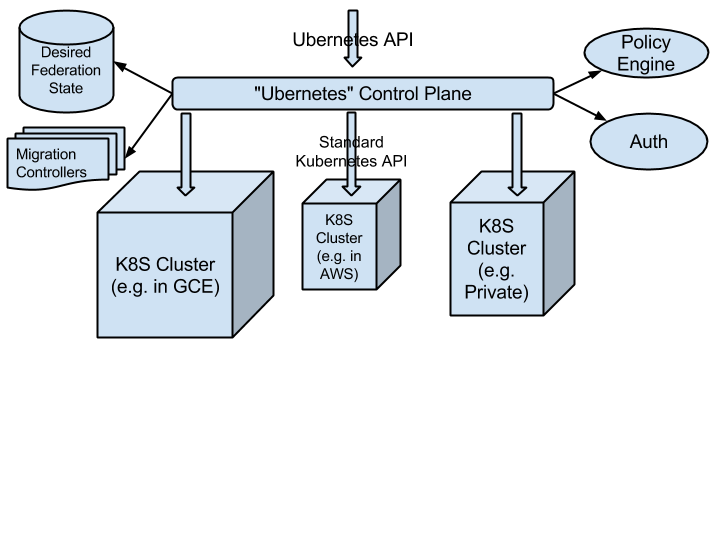
This looks a lot like the existing Kubernetes API but is explicitly multi-cluster.
The Policy Engine decides which parts of each application go into each cluster at any point in time, and stores this desired state in the Desired Federation State store (an etcd or similar). Migration/Replication Controllers reconcile this against the desired states stored in the underlying Kubernetes clusters (by watching both, and creating or updating the underlying Replication Controllers and related Services accordingly).
This should ideally be delegated to some external auth system, shared by the underlying clusters, to avoid duplication and inconsistency. Either that, or we end up with multilevel auth. Local readonly eventually consistent auth slaves in each cluster and in Ubernetes could potentially cache auth, to mitigate an SPOF auth system.
Identify concrete applications of each use case and configure a proof of concept service that exercises the use case. For example, cluster failure tolerance seems popular, so set up an apache frontend with replicas in each of three availability zones with either an Amazon Elastic Load Balancer or Google Cloud Load Balancer pointing at them? What does the zookeeper config look like for N=3 across 3 AZs -- and how does each replica find the other replicas and how do clients find their primary zookeeper replica? And now how do I do a shared, highly available redis database?